Cramped Room
Fast specialization and dense handoffs in a compact kitchen.
Representative Co-π-tree rollouts on the five benchmark layouts, followed by matching human-AI collaboration clips.
One representative mp4 for each Overcooked-AI layout.
Fast specialization and dense handoffs in a compact kitchen.
Partner-aware movement around a circular shared workspace.
Intent readability matters when counters become bottlenecks.
Different zones reward stable role decomposition.
Separated work areas demand complementary timing.
The same five layouts with a human partner interacting with Co-π-tree.
Human-AI handoffs in a high-contact layout.
Shared routing decisions with a human teammate.
Human-AI recovery around crowded counter flow.
Role asymmetry carries over to mixed human-AI play.
Coordinated alternation across split workspaces.
Existing zero-shot coordination methods often fall into two camps: MARL policies execute quickly but are difficult to interpret, while LLM-based agents expose language reasoning but query the model at every decision step. Co-π-tree uses LLMs to construct and revise the policy, then executes the learned tree directly.
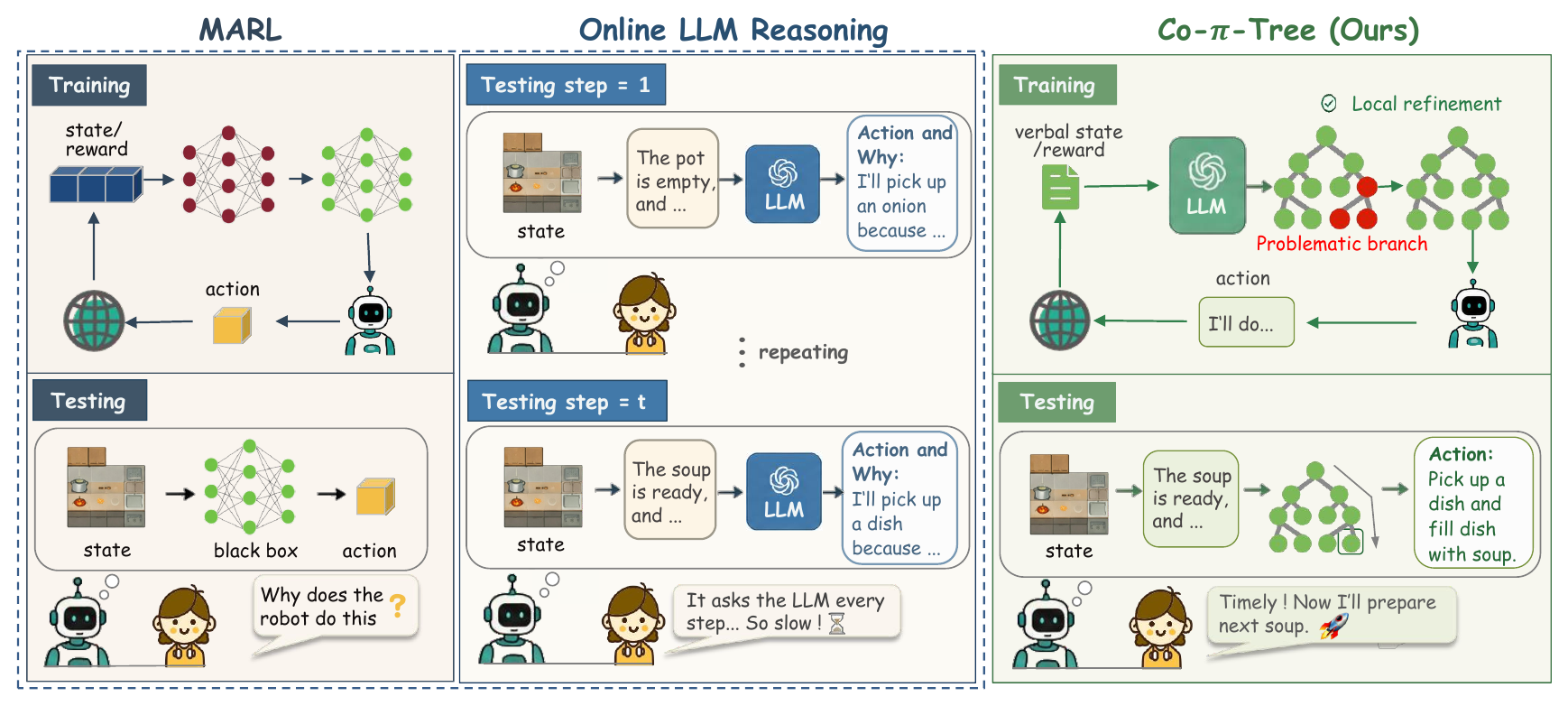
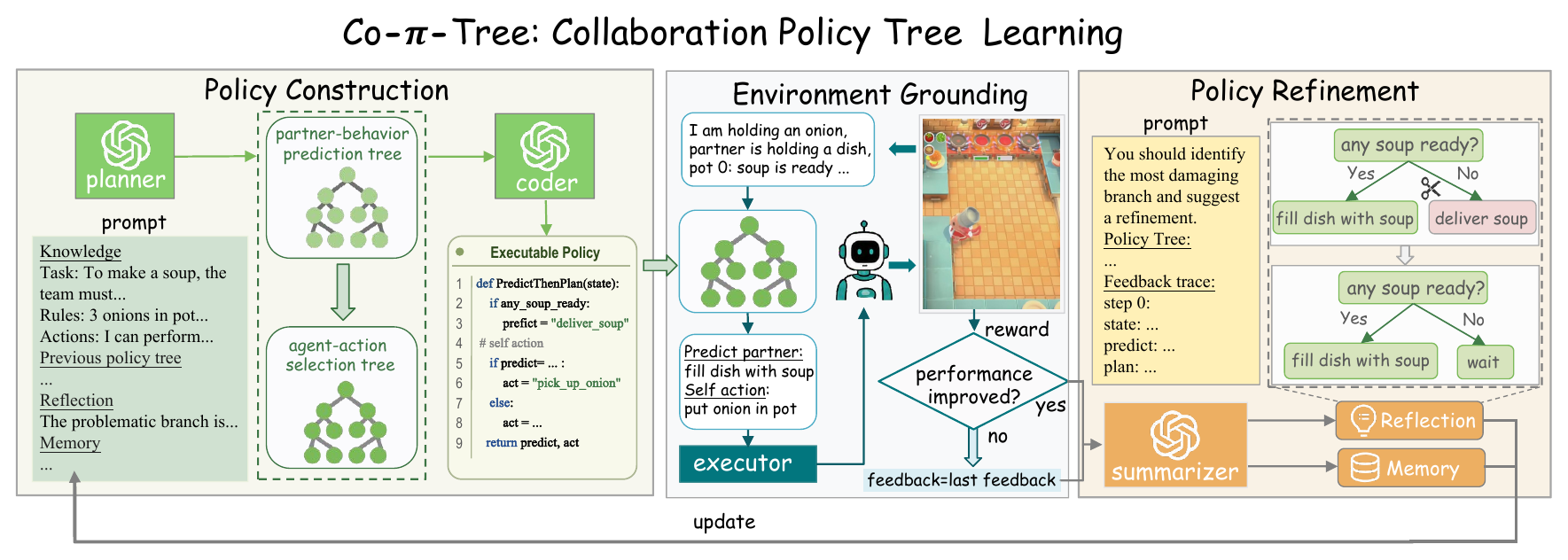
We evaluate in Overcooked-AI, a standard zero-shot coordination benchmark where two agents cooperate to cook and deliver soups under different layout constraints. The five layouts stress different collaboration skills, including fast handoff, bottleneck avoidance, role specialization, and forced interdependence.

average reward over the baseline average across AI-partner evaluations.
LLM query reduction relative to online LLM baselines.
test-time latency reduction after the policy tree is learned.
@misc{zhang2026distillingllmreasoninginterpretable,
title={Distilling LLM Reasoning into an Interpretable Policy Tree for Human-AI Collaboration},
author={Beiwen Zhang and Yongheng Liang and Guowei Zou and Haitao Wang and Hejun Wu},
year={2026},
eprint={2606.08596},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2606.08596},
}